추천 시스템(Recommend System)
이번에 진행할 것은 추천 시스템이다. 추천 시스템의 경우 몇 가지 방법이 있다.
간략하게 설명하면 비슷한 유저를 찾아서 그 유저가 좋아했던 콘텐츠를 추천해 주거나 어느 한 유저가 어떤 콘텐츠를 봤을 때 각 콘텐츠의 유사도를 분석하고 비슷한 콘텐츠를 추천해주는 방식이 있다. 이번에는 후자의 방식을 코드와 함께 소개하고자 한다.
1. 추천 시스템의 설명

위의 그림이 매우 간단하게 추천 시스템을 표현하는 그림이다. 유저B는 유저 A와 유사하다고 할 수 있고 따라서 유저 B에게 콜라를 추천해 줄 수 있는 것이다. 또한 반대로 라면을 먹은 유저들 대부분은 삼각김밥을 먹었기 때문에 유저D에게 삼각김밥을 추천해 줄 수 있는 것이다.
2. 추천 시스템의 알고리즘 및 Task
그럼 추천 시스템에서 머신러닝이 하는 역할은 무엇일까? 바로 위의 표에서 빈 공간을 채우거나 새로운 무언가가 들어왔을 때 하는 것이 바로 추천 시스템에서 인공지능의 역할이다. 위처럼 비어있는 공간이나 아니면 전혀 새로운 유저나 콘텐츠가 들어왔을 경우 아무런 정보 없이 그 선호도를 파악하기 위해 행렬 분해를 사용하고 각각을 채운다. 이는 나중에 논문과 코드를 리뷰해보면서 더욱 자세히 알아보도록 하겠다.
3. 기본적인 협업 필터링 구현 코드
본격적인 인공지능을 이용한 추천 시스템을 하기 전에 기본적인 협업 필터링을 통한 추천 시스템을 구현해 보도록 하겠다.
가장 먼저 데이터를 구비한다. 데이터는 다음과 같이 movie, rating 두가지 파일이 있고 각각은 다음과 같은 형태를 띈다.

movie.csv 파일
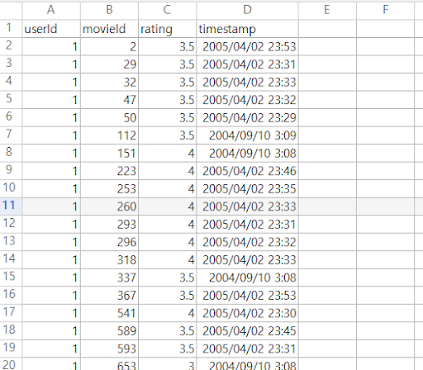
rating.csv 파일
보다 싶이 나누어서 영화 이름, 아이디, 장르와 관객 정보, 점수 등이 표시되어 있다. 이제 우리는 이 자료를 가지고 한 사용자에게 다른 영화를 추천해주는 알고리즘을 짜볼 것이다.
일단 사용할 기본적인 라이브러리들과 데이터를 불러왔다.
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
scoredata = pd.read_csv('./data/rating.csv')
moviedata = pd.read_csv('./data/movie.csv')
그리고 이제 데이터를 정제하겠다. 가장 먼저 위의 데이터에서 시간(timestap)는 크게 필요가 없는 데이터라고 판단되어 drop시켰다. 그 후 편하게 데이터를 확보하기 위해 두 자료를 판다스에서 제공하는 머지 함수를 이용하여 합쳤다.
scoredata = scoredata.drop(['timestamp'],axis='columns')
result = pd.merge(moviedata, scoredata, on="movieId", how="right")
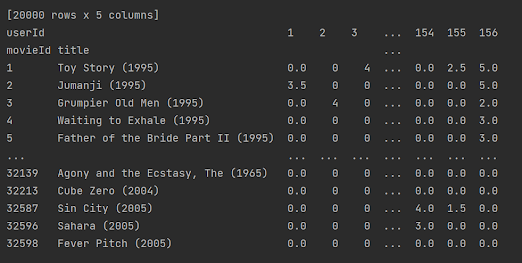
그리고는 데이터를 표의 형태로 맞추기 위해 피봇 테이블을 이용하였다. 그 결과는 다음과 같다.
scoretable = pd.pivot_table(
result,
columns='userId',
index = ['movieId','title'],
values='rating',
fill_value = 0
)

merge된 두 데이터
이제 각 영화마다 서로서로의 유사도를 비교하기 위해서 유사도를 구한다. 이때 나는 코사인 유사도 (csine_similarity)를 사용했다. 기타 다른 유사도는 나중에 다루도록 하겠다.
대략적으로 표현하면 다음과 같은 구성이다.
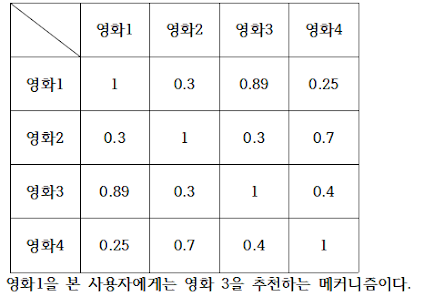
그리고 유사도는 위에서 언급했던 코사인 유사도를 사용했다. 따라서 코드는 다음과 같다.
sim = cosine_similarity(scoredata)
기존의 라이브러리를 사용해 쉽게 구할 수 있었다. 이를 통해 결과를 출력하면 다음과 같다.

위의 표와 같이 대각선을 기준으로 대칭인 것이 특징이다. 이제 이를 이용해 어느 한 영화가 들어오면 순위를 이용해 추천을 하면 되는 아주 간단한 방식이다.
추가적으로 그냥 일반 피봇으로 구성할 경우 거의 동일한 데이터를 얻을 수 있다.

scoredata = scoredata[:20000]
moviedata = moviedata[:10000]
이러면 모두 정상적으로 작동한다.
하지만 이런 방식에는 큰 문제점이 있다. 바로 새로운 콘텐츠나 이용자가 들어올 경우 그에 대한 자료를 얻을 수 있는 방법이 없다는 것이다. 따라서 이를 위한 방법이 필요하다. 그 방법은 추후 포스팅하도록 하겠다.
전체 코드는 깃허브에 업로드 되어있다.



댓글
댓글 쓰기